

Sommerblogg fra Norkarts internship studenter
Lillehammer 2021
Norkart Sommer er et internship program – hvor 12–15 dyktige studenter blir valgt av en solid søkerbunke med dyktige unge tech-spirer. En del av jobben deres er å formidle arbeidshverdagen og dele informasjon om prosjektene de jobber med her hos oss.
Her har vi bedt Lillehammer-gjengen om å gi oss et lite innblikk i hva de er opptatt av, og hvordan sommerjobb-hverdagen er i Norkart.

Fra venstre: André, Johannes og Vebjørn
Her er teamet
Velkommen til oss, sommerstudentene 2021 Team Lillehammer. Vi består av tre studenter som kommer fra forskjellige studieretninger. Vi har André T. Lønvik fra Master i Interaksjonsdesign, Johannes Padel fra Fysikk og Matematikk og Vebjørn F. Leiros som har en Bachelor i Programvareutvikling ved NTNU
Fjernavleste vannmålere – forbruk og miljøavtrykk
Vann er noe av det viktigste vi har her i Norge, og er noe vi alle trenger, drikkbart vann er dessverre ikke billig å produsere og det å følge med på eget forbruk er derfor enda viktigere. Nå som flere og flere har begynt å skaffe fjernavleste vannmålere har det blitt lettere å skaffe en nøyaktig måling for hvor mye vann som faktisk brukes, men problemet som har oppstått er da dessverre at det har blitt en ekstremt stor jobb for de få personene som jobber med dette.
Denne sommeren har vi brukt på å utvikle en prototype for å se hva som er mulig å gjøre med fjernavleste vannmålere. Dette har da gått inn på å analysere forbruk for å sikre at forbrukere er mer bevisst på sitt forbruk og miljøavtrykk
Et av punktene vi fokuserte på, var å kunne finne avvik i forbruket, slik at vi eventuelt kunne varsle enkelt personer raskere ved det tilfellet at de har, for eksempel en lekkasje. Vi har brukt tiden på å finne ut hvordan oppdage dette og hvordan vise dette på en god måte til en person.
Utfordringer underveis
Maskinlæring – Hvordan oppdage avvik fra normalt bruk
En interessant problemstilling som dukket opp er det å kunne klassifisere vannmålere etter forbruk, for å finne ut hvis vannmåleren er et avvik. Dette kan også være nyttig for å gi for eksempel en gjennomsnittlig familie et inntrykk av hvor mye vann de bruker sammenliknet med normalen, med et endelig mål om å potensielt kutte ned på forbruk.
Denne klassifiseringa ble det brukt en metode som heter for K-Means Clustering, som går ut på å automatisk dele inn i et bestemt antall grupperinger, basert på egenvalgte egenskaper til vannmåleren. Vi valgte tre grupperinger, lav, middels og høy, noe som er en ganske stor forenkling. Å dele inn i flere grupperinger er dog en veldig enkel implementasjon, så dette kan være et tankekors til fremtiden.
Noe annet spennende som kunne vært interessant å utforske videre er store, umiddelbare avvik, samt endringer i mekanismen som generer målingene. Disse kalles “spikes” og “trend changes”.
Å finne spikes kan være nyttig, hvis en husstand har et rør som plutselig blir ødelagt, men en problemstilling her er for eksempel at hvis en husstand fyller opp et badebasseng så vil det sannsynligvis også opptre som en spike. Derfor er dette et område som må behandles med omhu, det vil si at samtlige spikes ikke er nødt til å behandles som avvik.
Spikes ble funnet ved hjelp av Singular Spectrum Analysis, som er en matematisk metode innenfor tidsrekker som kan brukes til å finne usannsynlige målinger gitt de tidligere målingene. Selve metoden er ganske matematisk tung, men har gitt gode resultater.
For trend changes ble en en a-parametrisk metode kalt E-divisive pruned exact linear time brukt, med gode resultat. Den segmenter en tidsrekke med vannmålinger basert på like statistiske egenskaper, og tar hensyn til at f.eks èn “spike” ikke regnes som signifikant.
Dette er nyttig for å finne ut når store endringer i vannforbruk skjer, men er også avhengig av hva slags bolig som blir analysert. En fritidsbolig, eller hytte, vil sannsynligvis ikke ha noe vannforbruk store deler av året, men plutselig ha ganske mye (når eierne kommer på besøk). Derfor må dette området også behandles med omhu, men kan som sagt være nyttig for en overordnet analyse.

Mye tid brukes på drøfting og faglige diskusjoner
Prosessere store databaser
Det har vært spennende å ta i bruk det man har lært i databasefag i mer reelle tilfeller. Tidligere har man lært om metoder som man gjerne har testet på små databaser der responstiden er rask nesten uansett hva man gjør. Under dette prosjektet har vi møtt på utfordringer der vi var nøtt til å forbedre en rekke kall og tenke annerledes enn tidligere. Dette fordi vi behandlet data fra store databaser med millioner av rader.

Vebjørn tegner og forklarer
Hvem skal vi bygge for?
Et av spørsmålene vi måtte besvare ganske tidlig i ukene, var hvem skal vi egentlig fokusere på når vi lager dette? Vi hadde to mulige “kunder” å fokusere vår tid mot, enten ut mot enkeltpersoner eller inn mot saksbehandlere i kommunen (som følger med forbruket slik at alt fungerer slik det skal).
I et av våre mange møter fant vi ut at det var bedre for oss å fokusere mot saksbehandlere, ettersom de trengte mer data en én vanlig person. Dette gjorde at vi jobbet mer data-drevent og måtte vise data på en god måte. Det er lettere å fjerne data en det er å legge til, så å lage noe for den som trengte tilgang til mest var den riktige løsningen for oss.
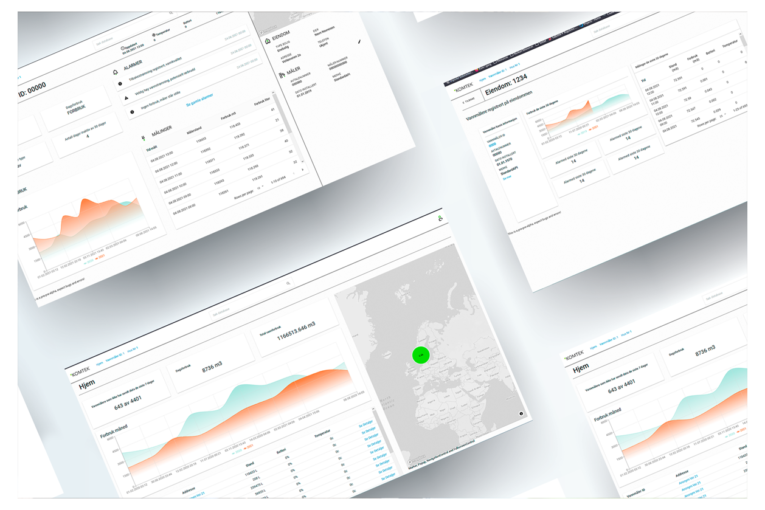
Ferdig produkt

Ferdig produkt